2
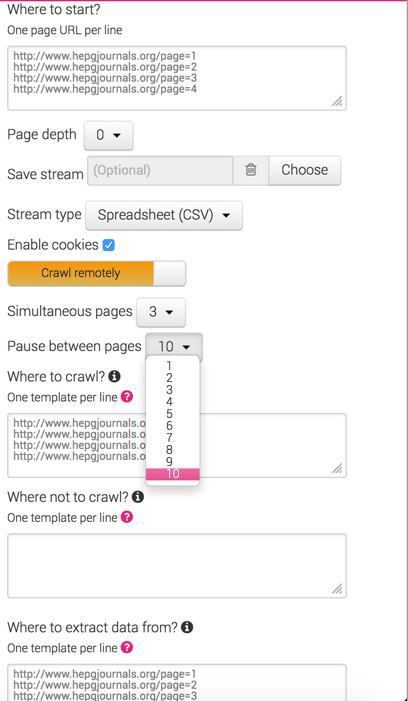
Итак, я довольно долго извлекаю много данных с помощью приложения desktop.index.io; но то, что всегда подслушивало меня, - это когда вы пытаетесь вывести несколько URL-адресов, они всегда пропускают половину из них.Предотвращение пропуски URL-адреса при сборе в массе с import.io
Это не проблема URL, если вы берете то же самое, скажем, 15 URL-адресов, которые будут возвращаться, например, в первый раз 8, второй раз 7, в третий раз 9; некоторые ссылки будут извлечены в первый раз, но будут пропущены второй раз и так далее.
Мне интересно, есть ли способ заставить его обрабатывать все URL-адреса, которые я им кормлю?
{kind=link}
Тем временем я тоже разрешил его с помощью Crawler, точно так же, как вы объяснили. – Dino