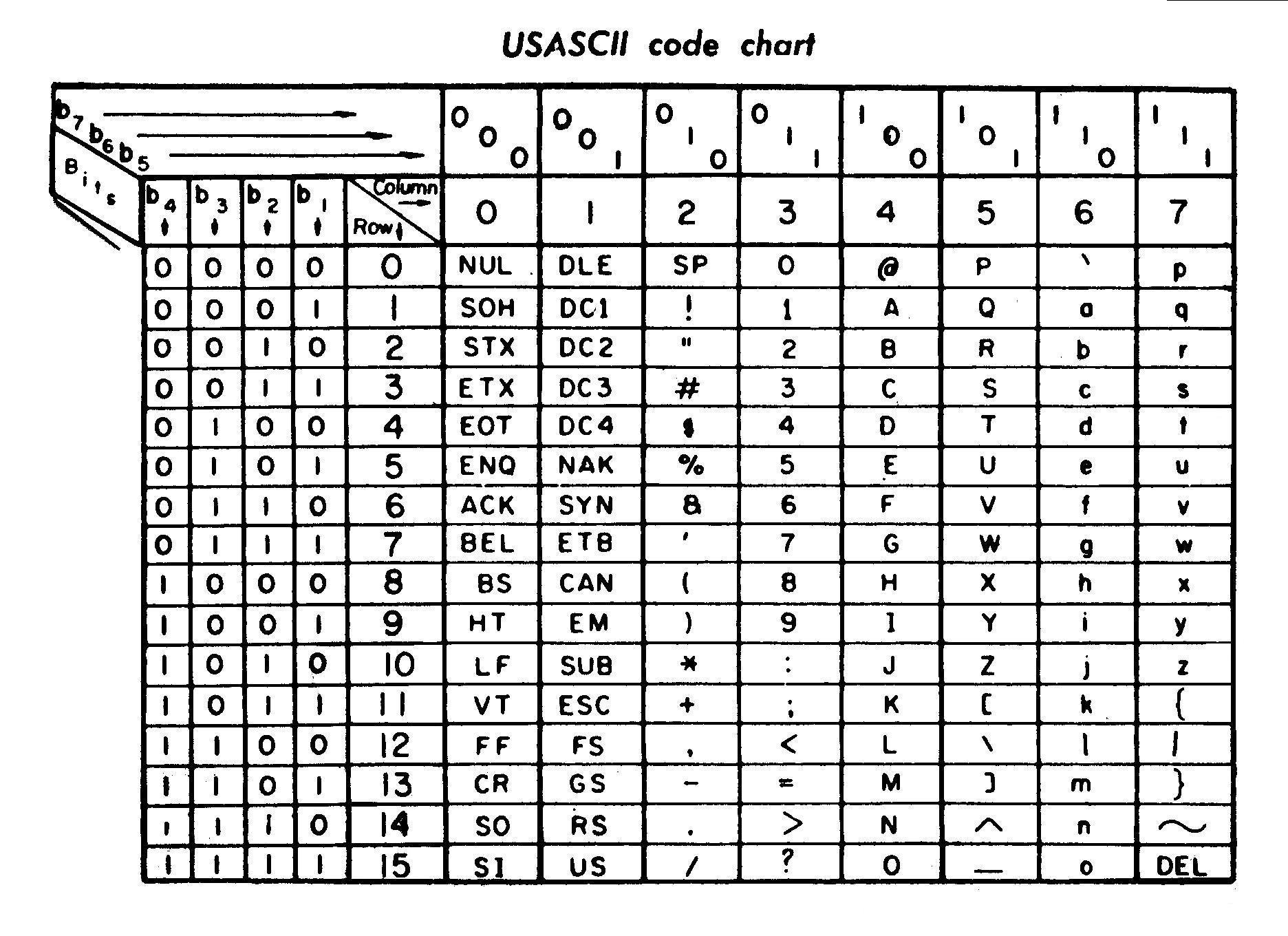
Я преподавал C моему младшему брату, изучающему инженерное дело. Я объяснял ему, как различные типы данных фактически хранятся в памяти. Я объяснил ему логистику за подписью/беззнаковым числом и битом с плавающей запятой в десятичных числах. Пока я рассказывал ему о типе char в C, я также брал его через систему кода ASCII, а также, как char также хранится как 1 байт.Есть ли какая-либо логика для заказа кодов ASCII?
Он спросил меня, почему «А» получил код ascii 65, а не что-нибудь еще? Аналогично, почему «а» задан код 97 конкретно? Почему существует пробел в 6 кодах ascii между диапазоном заглавных букв и маленькими буквами? Я понятия не имел об этом. Можете ли вы помочь мне понять это, так как это вызвало у меня большое любопытство. Я до сих пор не нашел ни одной книги, которая обсуждала эту тему.
В чем причина этого? Логически организованы коды ASCII?
Хотя хорошо говорить о поплавках и десятичных знаках нетехническим образом, большинство поплавков в дикой природе - это двоичная с плавающей запятой, а не десятичная плавающая точка, что является источником большого путаницы для программистов , Это похоже на учение о том, что солнце вращается вокруг Земли - прекрасно, чтобы дети понимали день и ночь, но путают для начинающих ученых-ракетологов. –
Связанные: [Все, что Хакер когда-то знал] (http://www.catb.org/esr/faqs/things-every-hacker-once-knew/) (о ASCII и связанных с ним технологиях) –