Я пытаюсь исключить группу слов, но включает в себя другую группу слов в выражении qregexp, но в настоящее время у меня возникают проблемы с этим.Как исключить один набор слов, но включить другой в qregexp?
Вот некоторые из вещей, которые я пробовал (этот пример включены все слова):
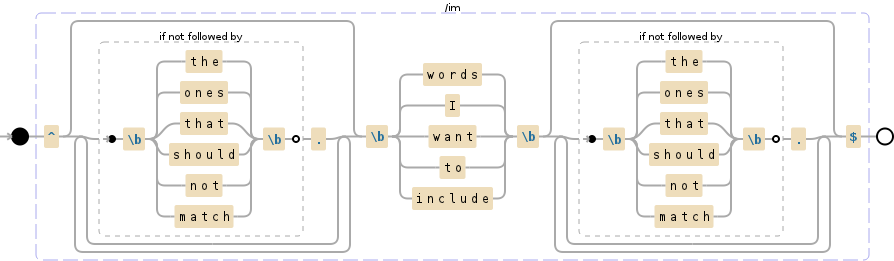
(words|I|want|to|include)(?!the|ones|that|should|not|match)
Так что я попробовал это (который не дал ничего):
^(words|I|want|to|include)(?:(?!the|ones|that|should|not|match).)*$
Могу ли я что-то отсутствует ?
Редактировать: причина, по которой мне нужно такое необычное регулярное выражение (include/exclude), заключается в том, что я хочу искать в серии статей и фильтровать те, которые содержат включенные в них слова, но нет, если они также имеют исключенные слова в них.
Так, например, если статья А:
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
и статья Б:
Vivamus fermentum semper porta.
Тогда регулярное выражение, которое включает в себя lorem бы фильтровать статью А, но не B. Но если ipsum является слово, которое я исключаю, я не хочу, чтобы статья А была отфильтрована.
Я рассмотрел возможность создания регулярных выражений, чтобы отфильтровывать статьи со словами, которые я хочу, а затем запускать второе регулярное выражение, исключая статьи из первого набора, которые я не хочу, но, к сожалению, используемое мной программное обеспечение не позволяет мне сделай это. Я могу запустить только одно регулярное выражение.
Это не имеет смысла. Вы явно перечисляете слова, которые хотите сопоставить («включить»). После этого нет необходимости «исключать» что-либо; вы уже знаете, что находится в вашем «белом списке». – melpomene
Что вы подразумеваете под включением? хотя бы одно слово из списка? –
Я использую это программное обеспечение RSS (QuiteRSS), которое позволяет отфильтровывать статьи с использованием qregexp, которые содержат определенные слова. Тем не менее, я не хочу, чтобы статьи, содержащие эти слова, были отфильтрованы, если слова в негативном обзоре также содержатся в статье. – thequerist