Это может быть лучший вопрос для CrossValidated, но:
- это не вообще хорошая идея, чтобы выбрать из целого ряда возможных распределений по доброте прилегания. Вместо этого, вы должны выбрать в соответствии с качественных характеристик данных, что-то вроде этого:
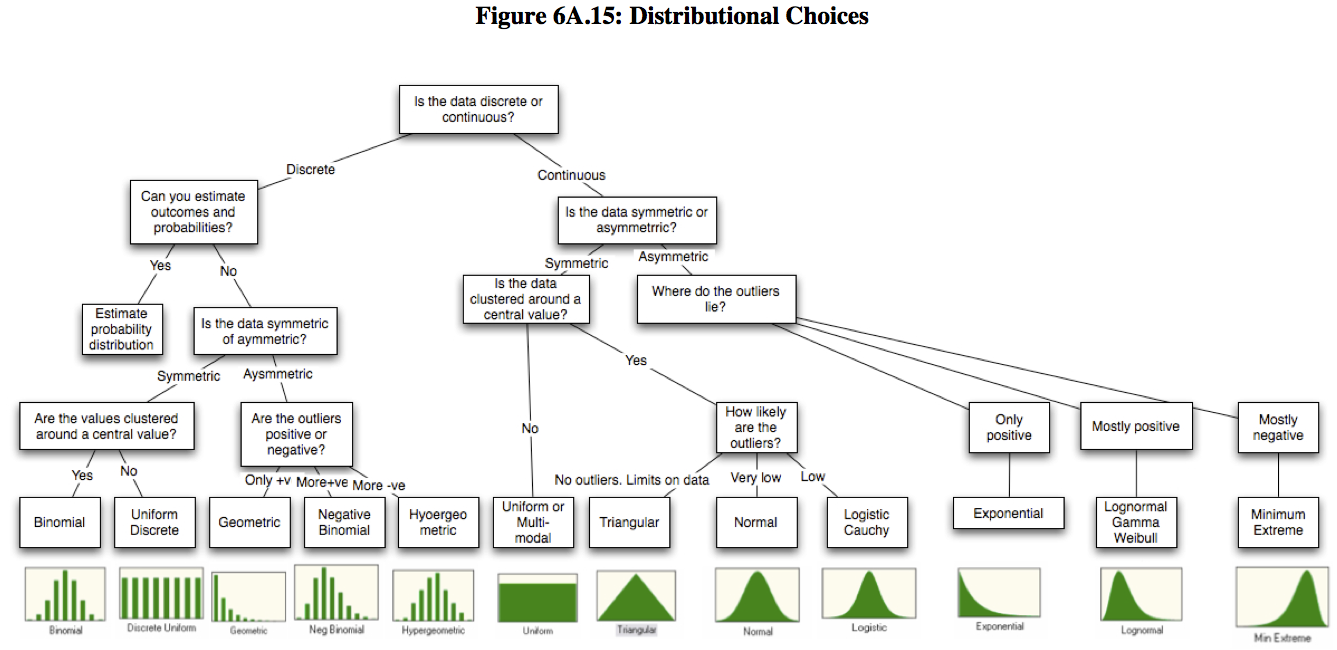
Разочаровывающе, эта диаграмма фактически не имеет лучший выбор для ваших данных (состава, непрерывное , ограниченное между 0 и 1 [или 0 и 100]), которое является Beta distribution (хотя есть технические проблемы, если в вашем примере есть значения ровно 0 или 100).
В R:
## some arbitrary data
z <- c(2,8,40,45,56,58,70,89)
## fit (beta values must be in (0,1), not (0,100), so divide by 100)
(m <- MASS::fitdistr(z/100,"beta",start=list(shape1=1,shape2=1)))
## sample 1000 new values
z_new <- 100*rbeta(n=1000,shape1=m$estimate["shape1"],
shape2=m$estimate["shape2"])
, когда вы говорите, «состав смеси» вы имеете в виду у вас есть одно измерение каждого наблюдения (например, ваши данные один вектор чисел, например, 21,2%, 3,2%, 46,7% , 54,1% ...), или у вас есть фракции разных компонентов, которые суммируются до 1 для каждого наблюдения ((2,5%, 90%, 7,5%), (10%, 90%, 0%), ...) ? –
Спасибо, я должен сделать анализ для одного образца (композиции), т. Е. У меня будут фракции компонентов, которые суммируются до 1 для каждого наблюдения (образца). Я должен иметь возможность тестировать распределение компонентов в каждом образце (композиции) отдельно. – Sequestrator