Поскольку ни один из других ответов на самом деле не объясняет, как что-то подобное можно реализовать, я дам ему шанс.
Одним из способов было бы иметь некоторую дополнительную информацию в значении (пары ключ-> значение), не видимой пользователю, которая имела ссылку на предыдущий и следующий элементы, вставленные в хэш-карту. Преимущества в том, что вы по-прежнему можете удалять элементы в постоянном времени. Удаление из хэш-карты - это постоянное время, и удаление из связанного списка в этом случае происходит потому, что у вас есть ссылка на запись. Вы можете по-прежнему вставлять в постоянное время, поскольку вставка карты хеш-памяти постоянна, связанный список обычно не выполняется, но в этом случае у вас есть постоянный доступ времени к месту в связанном списке, поэтому вы можете вставлять его в постоянное время, и, наконец, поиск является постоянным временем потому что вам нужно иметь дело с частью хэш-карты для структуры.
Имейте в виду, что структура данных, подобная этой, не поставляется без затрат. Размер хэш-карты значительно возрастет из-за всех дополнительных ссылок. Каждый из основных методов будет немного медленнее (может иметь значение, если они вызываются повторно). И косвенность структуры данных (не уверен, что это реальный термин: P) увеличивается, хотя это может быть не так уж и сложным, потому что ссылки гарантированно указывают на вещи внутри хэш-карты.
Поскольку единственным преимуществом такого типа конструкции является то, что он сохраняет порядок, будьте осторожны, когда вы его используете. Также, читая ответ, помните, я не знаю, что так оно и было реализовано, но я бы это сделал, если задал задачу.
На oracle docs есть цитата, подтверждающие некоторые из моих догадок.
Эта реализация отличается от HashMap тем, что она поддерживает список с двойной связью, проходящий через все его записи.
Другая соответствующая цитата с того же сайта.
Этот класс предоставляет все необязательные операции карты и допускает нулевые элементы. Как и HashMap, он обеспечивает постоянную производительность для основных операций (добавлять, содержать и удалять), предполагая, что хеш-функция правильно распределяет элементы среди ведер. Производительность, вероятно, будет чуть ниже, чем у HashMap, из-за дополнительных затрат на поддержание связанного списка, за одним исключением: Итерация над представлениями коллекции LinkedHashMap требует времени, пропорционального размеру карты, независимо от ее емкости , Итерация над HashMap, вероятно, будет более дорогой, требуя времени, пропорционального ее пропускной способности.
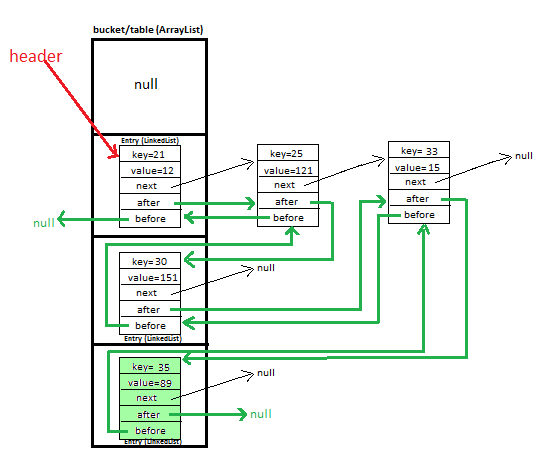
Просто угадайте, но внутри каждой пары ключ-> значение значение сохраняет следующий и предыдущий указатель на другие записи, чтобы сохранить порядок вставки, это сохраняет порядок и по-прежнему позволяет вставлять и извлекать постоянное время удаления – aaronman
ok. Я просто думал об этом. Итак, каждый объект «Entry» в массиве имеет ссылку на следующий и предыдущий объект Entry? – Mercenary
Я добавляю ответ, чтобы лучше объяснить его – aaronman