Итак, я хочу искать A, B, C, D в строке в любом порядке, но если C не существует, я все равно хочу, чтобы он дал мне A, B и D и т. Д.Может ли регулярные выражения искать группы независимо от порядка или все они существуют?
To более конкретно, вот точная проблема, которую я пытаюсь решить. CSV-файл с строками, которые выглядят так:
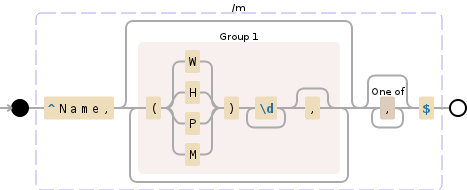
Name,(W)5555555,(H)5555555,(M)5555555,(P)5555555
Однако W, H, M, P может быть в любом порядке. Плюс они не все существуют на каждой линии. Так это выглядит примерно так:
Name,(W)5555555,(H)5555555,(M)5555555,(P)5555555
Name,(H)5555555,(P)5555555,(W)5555555,(M)5555555
Name,(M)5555555,(H)5555555,,
Name,(P)5555555,,,
Что мне нужно выполнить, чтобы поместить все элементы в правильном порядке, чтобы они выстраиваются под правильными колоннами. Таким образом, выше должен выглядеть следующим образом, когда я сделал:
Name,(W)5555555,(H)5555555,(M)5555555,(P)5555555
Name,(W)5555555,(H)5555555,(M)5555555,(P)5555555
Name,,(H)5555555,(M)5555555,
Name,,,,(P)5555555
Edit: Оказывается я плохой Stack Overflow гражданин. Я не получал ответов достаточно быстро, когда мой проект нужно было сделать, и поэтому забыл вернуться и добавить правильные вопросы в свой пост. Я закончил писать сценарий python для этого, вместо того, чтобы просто использовать find/replace в BBEdit или Sublime Text 2, как я изначально пытался сделать.
Таким образом, мне нужен способ сделать что-то подобное, что работает либо в BBEdit, либо в Sublime Text. Или Вим, если на то пошло. На этот раз я постараюсь лучше взглянуть на него, и я отвечу на ответы, которые уже существуют.
Чтобы процитировать описание тега 'regex': * Также укажите тег, определяющий язык программирования или инструмент, который вы используете. * –
Было бы хорошо, если бы вы могли включить в свой вопрос язык, который вы используете, и ваши попытки (ы) до сих пор. – Jerry
Безусловно выполнимо.Понятно, что вам нужно рассматривать каждый элемент как отдельный запрос, а затем хранить результаты в каком-либо структурированном объекте, будь то в базе данных или в массиве/списке/словаре/и т. Д. Затем вам нужно будет перезаписать CSV-файл. Я не уверен, что регулярные выражения - лучший инструмент для этой работы, если вы действительно не ищете * шаблоны * вместо конкретных разделителей, таких как 'W',' H', 'M' и т. Д. –