на самом деле это не представляется возможным сделать это с помощью регулярных выражений, поскольку регулярные выражения выражают язык, определенный регулярной грамматики, которая может быть решена при помощи, не конечный детерминированным автомата, где согласование представлены государствами; то для соответствия вложенным скобкам вам нужно будет иметь возможность сопоставить бесконечное число скобок и затем иметь автомат с бесконечным числом состояний.
Чтобы быть в состоянии справиться с этим, мы используем то, что называется пуш-вниз автомат, который используется для определения контекстно-свободной грамматики.
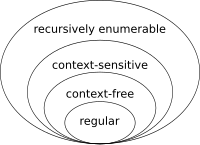
Так что, если ваш регулярное выражение не совпадает с вложенной скобкой, это потому, что это выражающее следующий автомат и ничего не найдено на вашем входе:

Play with it
As ссылку, пожалуйста, ознакомьтесь с курсами MIT по теме:
Так один из способов эффективного разбора вашей строки, чтобы построить грамматику для вложенной скобки (pip install pyparsing первой):
>>> import pyparsing
>>> strings = pyparsing.Word(pyparsing.alphanums)
>>> parens = pyparsing.nestedExpr('(', ')', content=strings)
>>> parens.parseString('(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))').asList()
[['NP', ['NNP', 'Hoi'], ['NN', 'Hallo'], ['NN', 'Hey'], ['NNP', ['NN', 'Ciao'], ['NN', 'Adios']]]]
NB: существует несколько механизмов регулярных выражений, которые реализуют вложенные скобки с использованием push do шп. Питон по умолчанию re двигателя не один из них, но существует альтернативный двигатель, названный regex (pip install regex), что может сделать рекурсивное согласование (что делает контекст повторного двигателя бесплатно), ср this code snippet:
>>> import regex
>>> res = regex.search(r'(?<rec>\((?:[^()]++|(?&rec))*\))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))')
>>> res.captures('rec')
['(NNP Hoi)', '(NN Hallo)', '(NN Hey)', '(NN Ciao)', '(NN Adios)', '(NNP (NN Ciao) (NN Adios))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))']
Это «Двоичный» ... – ThiefMaster