У меня был этот вопрос в течение нескольких месяцев. Похоже, мы просто ловко угадали softmax как функцию вывода, а затем интерпретировали входной сигнал softmax как логарифмические вероятности. Как вы сказали, почему бы просто не нормализовать все выходы, разделив их на сумму? Я нашел ответ в Deep Learning book Гудфеллоу, Бенгио и Курвилле (2016 год) в разделе 6.2.2.
Скажем, наш последний скрытый слой дает нам z как активацию.Затем SoftMax определяется как

Очень краткое объяснение
ехр в SoftMax функции примерно отменяет журнал в кросс-энтропии потери, вызывая потерю быть примерно линейно по z_i. Это приводит к грубому постоянному градиенту, когда модель ошибочна, что позволяет быстро исправлять ее. Таким образом, неправильный насыщенный softmax не вызывает исчезающего градиента.
Краткое объяснение
Самого популярный метод для обучения нейронной сети является максимальным правдоподобием Оценки. Мы оцениваем параметры тета таким образом, чтобы максимизировать вероятность данных обучения (размера m). Поскольку вероятность того, что весь набор данных обучения является продуктом вероятности каждого образца, легче максимизировать лог-правдоподобие набора данных и, таким образом, сумму логарифмической вероятности каждого образца, проиндексированного по k:
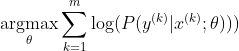
Теперь мы сосредоточимся только на SoftMax здесь с г уже дали, поэтому мы можем заменить
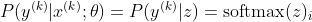
с я быть правильный класс образца -го. Теперь мы видим, что, когда мы берем логарифм SoftMax, чтобы вычислить логарифмическую вероятность сэмпла, получим:
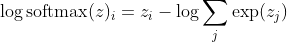
, что для больших различий в г примерно приближается к
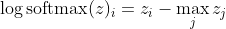
Сначала мы видим здесь линейную составляющую z_i. Во-вторых, мы можем изучить поведение max (z) для двух случаев:
- Если модель верна, то max (z) будет z_i. Таким образом, лог-правдоподобие асимптотирует нуль с растущей разницей между z_i и другими элементами в z.
- Если модель неверна, то max (z) будет другим z_j> z_i. Таким образом, добавление z_i не полностью отменяет -z_j, а потери грубо - (z_j - z_i).
Мы видим, что общее логарифмическое правдоподобие будет определяться образцами, где модель неверна. Кроме того, даже если модель действительно неверна, что приводит к насыщенному softmax, функция потерь не насыщается. Он приблизительно линейный по z_j, что означает, что мы имеем примерно постоянный градиент. Это позволяет быстро скорректировать модель. Обратите внимание, что это не относится к среднему квадрату ошибки, например.
Long Объяснение
Если SoftMax все еще кажется, что произвольный выбор для вас, вы можете посмотреть на обоснование использования сигмовидной в логистической регрессии:
Why sigmoid function instead of anything else?
SoftMax является обобщение сигмоида для многоклассовых задач оправдано аналогично.



Функция вычисляется не дорого из-за экспонентов, а потому, что вам нужно вычислить каждый qj. Экспоненциация является дешевой по сравнению с общим количеством необходимых вычислений. –