Чтобы ответить на ваш вопрос, вам сначала нужно понять, как работает KNN. Вот простая схема:
http://www.vias.org/tmdatanaleng/img/hl_knn.png
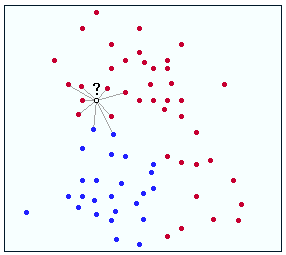
предполагало? это то, что вы пытаетесь классифицировать как красным, так и синим. В этом случае предположим, что вы не нормализировали ни одну из данных. Как вы можете ясно видеть? ближе к более красным точкам, чем синие боты. Поэтому этот пункт считается красным. Предположим также, что правильная метка красная, поэтому это правильное совпадение!
Теперь, чтобы обсудить нормализацию. Нормализация - это способ получения данных, которые немного отличаются друг от друга, но придают ему общее состояние (в вашем случае подумайте о том, как сделать функции более похожими). Предположим в приведенном выше примере, что вы нормализуете функции?, И поэтому выходное значение y становится меньше. Это поставило бы знак вопроса ниже текущей позиции и окружили более синими точками. Поэтому ваш алгот будет обозначать его как синий, и это было бы неправильно. Ой!
Теперь, чтобы ответить на ваши вопросы. Извините, но ответа нет! Иногда нормализация данных устраняет важные отличия, что приводит к снижению точности. В других случаях это помогает устранить шум в ваших функциях, которые вызывают неправильные классификации. Кроме того, только потому, что точность повышается для набора данных, с которым вы в настоящее время работаете, не означает, что вы получите те же результаты с другим набором данных.
Короче говоря, вместо того, чтобы пытаться обозначить нормализацию как хорошие/плохие, вместо этого рассмотрите входы функций, которые вы используете для классификации, определите, какие из них важны для вашей модели, и убедитесь, что различия в этих функциях точно отражены в вашей классификации. Удачи!
{kind=link}
Это вопрос для http://stats.stackexchange.com. –
Точность только в наборе учебных материалов сама по себе не является хорошей мерой качества модели. Чтобы ответить на ваши вопросы и вести свою работу, вам также необходимо использовать другой набор данных, чем то, на что вы обучали модель, так называемый набор данных проверки или набор данных тестирования. –